Wprowadzenie do klasyfikacji
Celem laboratorium jest przedstawienie podstawowych pojęć wykorzystywanych w zadaniach klasyfikacji, takich jak: zbiór uczący, zbiór testujący, walidacja krzyżowa, czy macierz pomyłek. W trakcie laboratorium sprawdzamy, jak wykonać najbardziej podstawowe algorytmy klasyfikacji w środowiskach Orange Data Mining i RapidMiner.
Orange Data Mining
- Uruchom narzędzie Orange Data Mining i korzystając z operatora
Filezaładuj zbiór titanic.tab. Prześlij zbiór do operatoraData Tablei zapoznaj się z jego charakterystyką. Wykorzystaj znane Ci narzędzia do wizualizacji aby lepiej poznać rozkłady poszczególnych zmiennych. - Wyślij dane do operatora
Train and Score. - Dodaj do przepływu operator
Constanti prześlij jego wynik do operatoraTrain and Score. Obejrzyj zawartość operatoraTrain and Score. Czy potrafisz powiedzieć, dlaczego dokładność klasyfikacji (CA) wynosi 67.7%? - Dodaj operator
Confusion Matrixi prześlij do niego wynik operatoraTrain and Score. Spróbuj samodzielnie zinterpretować uzyskaną macierz pomyłek. - Dodaj operatory
Trainik-NNi prześlij je do operatoraTrain and Score. Porównaj główne metryki trzech modeli wewnątrz operatoraTrain and Score. - Zmień sposób podziału danych na zbiór uczący i testujący. Sprawdź, czy zauważasz istotne różnice jeśli chodzi o trafność klasyfikacji. Co się dzieje, gdy testowanie odbywa się na zbiorze trenującym?
- Sprawdź w jaki sposób wybór liczby podziałów (k-folds) w walidacji krzyżowej wpływa na trafność klasyfikacji.
- Dodaj do przepływu operator
ROC Analysisi porównaj ze sobą trzy analizowane modele klasyfikacji. - Dodaj do przepływu operator
Calibration Plti sprawdź, w jakich zakresach modele są nadmiernie pesymistyczne/optymistyczne. - Dodaj do przepływu operator
Predictionsi zaobserwuj, w jaki sposób poszczególne modele dokonują predykcji dla instancji. - Twój ostateczny przepływ powinien wyglądać następująco:

RapidMiner
- Uruchom narzędzie Rapid Miner
- Znajdź operator
Generate Data. Wskaż jako liczbę generowanych obiektów 1000, a jako funkcję zmiennej celu podaj two gaussians classification. Liczbę atrybutów ustaw na 2, ich zakres możesz zostawić z wartościami domyślnymi. Uruchom swój przepływ i obejrzyj wygenerowany zbiór danych. Zmień funkcję zmiennej celu na gaussian mixture clusters i jeszcze raz obejrzyj wynik. - Wstaw do przepływu operator
Split Validationi ustaw proporcje 60%-40%. Zauważ, że jest to operator dominujący, który wymaga sprecyzowania operatorów wewnętrznych. - Kliknij dwukrotnie na operatorze
Split Validation. W sekcjiTrainingumieść operatorRule Inductioni prześlij na wejście operatora zbiór trenujący, zaś wyjście operatora oznaczonemod(model) przekaż dalej. - W sekcji
Testingumieść sekwencję operatorówApply ModeliPerformance (Classification), przesyłając do operatoraApply Modelprzepływymodites(testing set). Etykietowane dane z operatoraApply Model(portlab(labeled data)) przekaż do operatoraPerformance (Classification). Port wyjściowyper(performance vector) przekaż jako wynik działania całego operatora złożonego.
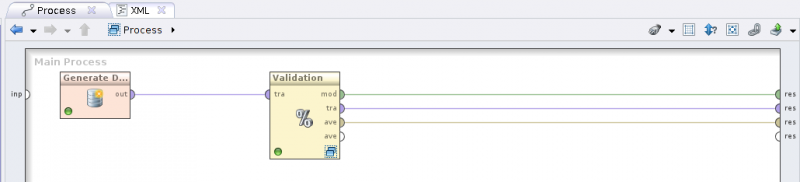
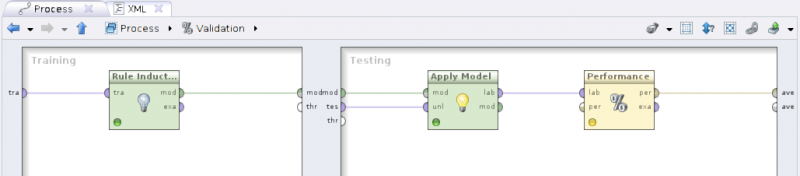
- Uruchom przepływ i zaobserwuj uzyskane wyniki.
- Zamień operator
Split ValidationnaX-Validationustawiając 10-krotną walidację krzyżową. Zamień zbiór danych naIris, a algorytm do klasyfikacji kolejno naTree to Rules(to także operator dominujący, do środka możesz wstawićDecision TreelubRandom Tree) ik-NN. Za każdym razem sprawdź uzyskiwane wyniki.
zadanie samodzielne (10 XP)
Pobierz zbiór danych winequality-white.csv i zapoznaj się z jego opisem. Stwórz w narzędziu RapidMiner przepływ importujący ten zbiór danych. Wykorzystaj operator Read CSV do wczytania danych, a następnie dokonaj dyskretyzacji atrybutu quality przy użyciu operatora Discretize by User Specification, przyjmując cztery klasy jakości: słabe (0,4), średnie (5,6), dobre (7,8), bardzo dobre (9,10). Wykorzystaj operator Set Role do wskazania, który atrybut jest zmienną zależną). Używając dowolnego z omówionych w trakcie laboratorium algorytmów klasyfikacji postaraj się uzyskać najwyższą ogólną dokładność klasyfikacji, przy czym możesz manipulować algorytmami klasyfikującymi i ich parametrami, a także metodą konstrukcji zbioru uczącego i testującego. Nie wolno Ci jednak testować klasyfikatora na zbiorze uczącym!
Odpowiedź w postaci pliku pdf imie-nazwisko.pdf załaduj do współdzielonego folderu Google Drive. W pliku umieść zrzuty ekranu z przepływu oraz (koniecznie) zrzut ekranu macierzy pomyłek. Termin wysłania zadania upływa w niedzielę, 3 maja 2020, godz. 21:00.