Wprowadzenie do klasyfikacji
Celem laboratorium jest przedstawienie podstawowych pojęć wykorzystywanych w zadaniach klasyfikacji, takich jak: zbiór uczący, zbiór testujący, czy walidacja krzyżowa. W trakcie laboratorium sprawdzamy, jak wykonać najbardziej podstawowe algorytmy klasyfikacji w środowiskach Weka i RapidMiner.
Weka
- Uruchom narzędzie Weka::Explorer
- Kliknij przycisk
Generatew górnym panelu. Z listy dostępnych generatorów wybierz operatorAgrawal, a następnie kliknij na nazwę operatora aby edytować jego własności. Zwiększ liczbę generowanych rekordów do 1000 i jako nazwę relacji podaj People. Naciśnij ponownie przyciskGenearteaby wygenerować zbiór danych. Obejrzyj informacje wyświetlane dla pojedynczego atrybutu. Zauważ, że Weka automatycznie jako zmienną celu wskazuje ostatni atrybut na liście atrybutów. - Dokonaj dyskretyzacji atrybutów numerycznych na trzy przedziały o równej szerokości. W tym celu na zakładce Preprocess kliknij przycisk
Choosei znajdź operatorFilters : Unsupervised : Attribute : Discretize, a następnie kliknij na nazwę operatora żeby edytować jego własności. Po ustawieniu parametrów nie zapomnij kliknąć na przyciskApply. Zobacz, jak zmieniły się atrybutySalaryiCommission. - Przejdź do zakładki
Classify. Kliknij przyciskChoosei z listy dostępnych klasyfikatorów wybierz operatorClassifiers : Rules : ZeroR. Zaznacz opcję Use training set w sekcji Test options i kliknij przyciskStart. Przeanalizuj uzyskane wyniki. Następnie zmień sposób generowania zbioru testowego na Percentage split i przyjmij, że uczenie odbędzie się na 20% oryginalnych danych. Porównaj wyniki klasyfikacji uzyskane teraz i w przypadku korzystania ze zbioru uczącego. Który wynik jest Twoim zdaniem bardziej wiarygodny? - Kliknij przycisk
Choosei zmień używany klasyfikator na operatorOne-R. Tym razem skonstruujesz zbiór testowy za pomocą metody 10-krotnej walidacji krzyżowej. Zbuduj model i postaraj się samodzielnie stwierdzić, na jakiej podstawie ludzie są przypisywani do jednej z grup. Sprawdź, w jaki sposób liczba grup przy konstrukcji zbioru testowego wpływa na trafność klasyfikacji. Starannie przeanalizuj raport dostarczony przez narzędzie i obejrzyj wynikową macierz pomyłek. Czy ta macierz jest wystarczająca, aby uznać klasyfikator za bardzo dobry?

- Uruchom algorytm klasyfikacji
Decision Table. W ustawieniach algorytmu włącz wyświetlanie znalezionych reguł decyzyjnych. Jaki atrybut jest wykorzystywany do zbudowania tablicy decyzyjnej? Wróć do zakładkiPreprocessingi usuń ten atrybut, a następnie powtórz budowanie modelu. Porównaj uzyskane wyniki. - W tej chwili poszukiwanie reguł decyzyjnych odbywa się za pomocą zachłannej metody
BestFirst. Sprawdź, czy zamiana procedury przeszukiwania przestrzeni rozwiązań na przeszukiwanie pełne (ang. Exhaustive Search) poprawi uzyskany wynik. - Usuń ze zbioru danych atrybuty
ageicara następnie uruchom algorytm klasyfikacjiPART. Obejrzyj uzyskane reguły decyzyjne. - Odtwórz oryginalny zbiór danych i przetestuj działanie klasyfikatorów
IB1iIBk. Postaraj się tak dobrać wartość parametru k aby uzyskać jak najwyższą dokładność klasyfikacji.
- Uruchom narzędzie Weka::Experimenter
- Na zakładce
Setupkliknij przyciskNewi utwórz nową konfigurację eksperymentu. - W polu
Datasetsumieść (za pomocą przyciskuAdd new…) zbiory weather.arff, vote.arff oraz labor.arff - W polu
Algorithmsumieść algorytmyZero-R,One-R,Decision Table,PARTorazIB1iIBk - W polu
Results destinationwybierz jako formatARFF filei podaj ścieżkę do pliku na lokalnym dysku (ten plik zostanie utworzony w wyniku uruchomienia eksperymentu). Liczbę powtórzeń eksperymentu ustaw na 10 - Przejdź na zakładkę
Runi kliknij przyciskStart - Przejdź na zakładkę
Analyzei wczytaj plik wynikowy. Upewnij się, że punktem odniesienia do oceny algorytmów jest proste głosowanie większościowe (Zero-R). Metodą porównywania wyników eksperymentu powinien być sparowany test Studenta. Uruchom test klikając na przyciskPerform test. - Sprawdź, jak zachowują się poszczególne algorytmy i który z nich jest “najlepszy”, manipulując też poziomem ufności. Zmień kryterium porównywania algorytmów na zwrot (ang. IR_recall).


Rapid Miner
- Uruchom narzędzie Rapid Miner 5
- Znajdź operator
Generate Data. Wskaż jako liczbę generowanych obiektów 1000, a jako funkcję zmiennej celu podaj two gaussians classification. Liczbę atrybutów ustaw na 2, ich zakres możesz zostawić z wartościami domyślnymi. Uruchom swój przepływ i obejrzyj wygenerowany zbiór danych. Zmień funkcję zmiennej celu na gaussian mixture clusters i jeszcze raz obejrzyj wynik. - Wstaw do przepływu operator
Split Validationi ustaw proporcje 60%-40%. Zauważ, że jest to operator dominujący, który wymaga sprecyzowania operatorów wewnętrznych. - Kliknij dwukrotnie na operatorze
Split Validation. W sekcjiTrainingumieść operatorRule Inductioni prześlij na wejście operatora zbiór trenujący, zaś wyjście operatora oznaczonemod(model) przekaż dalej. - W sekcji
Testingumieść sekwencję operatorówApply ModeliPerformance (Classification), przesyłając do operatoraApply Modelprzepływymodites(testing set). Etykietowane dane z operatoraApply Model(portlab(labeled data)) przekaż do operatoraPerformance (Classification). Port wyjściowyper(performance vector) przekaż jako wynik działania całego operatora złożonego.
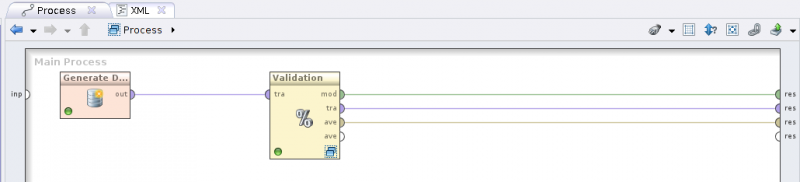
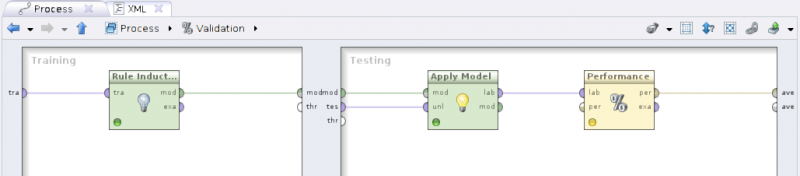
- Uruchom przepływ i zaobserwuj uzyskane wyniki.
- Zamień operator
Split ValidationnaX-Validationustawiając 10-krotną walidację krzyżową. Zamień zbiór danych naIris, a algorytm do klasyfikacji kolejno naTree to Rules(to także operator dominujący, do środka możesz wstawićDecision TreelubRandom Tree) ik-NN. Za każdym razem sprawdź uzyskiwane wyniki.
Except where otherwise noted, content on this wiki is licensed under the following license:Public Domain