Naiwny klasyfikator Bayesa
W trakcie laboratorium uczymy się wygrywać w telewizyjnych teleturniejach, zgadywać do jakiej gromady należą nietoperze, ale też poznajemy naiwny klasyfikator Bayesa i sprawdzamy, jak ten model klasyfikatora zachowuje się na wybranych zbiorach danych.
dla zapominalskich

Przećwiczmy co to znaczy na przykładzie.
| nazwa | narodziny | ssie mleko? | liczba nóg | czy lata? | gromada |
|---|---|---|---|---|---|
| mysz | żywe | tak | 4 | nie | ssaki |
| lew | żywe | tak | 4 | nie | ssaki |
| wieloryb | żywe | tak | 2 | nie | ssaki |
| kiwi | jajo | nie | 2 | nie | ptaki |
| orzeł | jajo | nie | 2 | tak | ptaki |
| bocian | jajo | nie | 2 | tak | ptaki |
| nietoperz | żywe | tak | 2 | tak | ??? |
Rapid Miner
- Uruchom narzędzie Rapid Miner
- Pobierz plik danych zoo.arff
- Utwórz przepływ realizujący najprostsze zadanie klasyfikacji przy wykorzystaniu naiwnego klasyfikatora Bayesa. W tym celu wykorzystaj operator
Read ARFFdo załadowania zbioru danych, a następnie przekaż zbiór danych do operatoraSet Role, w którym wskaż atrybuttypejako pełniący rolę zmiennej celu (ang. label). Dodatkowo, atrybut animal wskaż jako atrybut pełniący rolę identyfikatora. Tak zmodyfikowany zbiór danych prześlij do operatoraNaive Bayesi uruchom przepływ. - Przełącz się na widok Plot View i obejrzyj rozkłady wartości zmiennej celu względem atrybutu feathers lub fins. Porównaj te rozkłady z rozkładami wzlgędem zmiennej predator. Obejrzyj też rozkłady dla atrybutu numerycznego legs.
- Przełącz się na widok Distribution Table. Jakie cechy są wspólne dla wszystkich ptaków?
- Zamień operator klasyfikatora na operator
Cross-Validation, w fazie uczenia tego operatora umieść właśnie operator naiwnego klasyfikatora Bayesa, a w fazie testowania następujące po sobie operatoryApply ModeliPerformance (Classification). Twój przepływ powinien wyglądać tak:


- Wstaw do fazy uczenia operatora
Cross-Validationdrugi operator realizujący model klasyfikatora bazującego na indukcji reguł (operatorRule Induction). Wyłącz operatorNaive Bayes Classifier(z menu kontekstowego operatora wybierz opcjęEnable Operator) i w jego miejsce wstaw operator indukcji reguł. Porównaj dokładność naiwnego klasyfikatora Bayesa i dokładność uzyskaną przez algorytm indukcji reguł. - Wprowadź do przepływu szum informacyjny zmieniając losowo 20% etykiet zwierząt. Ponownie porównaj wyniki uzyskiwane przez oba modele klasyfikacji.
Orange Data Mining

- Uruchom narzędzie Orange Data Mining i załaduj zbiór danych titanic.tab. Obejrzyj dane przy pomocy operatora
Data Table. Możesz także posłużyć się operatoremStatisticsdo zapoznania się z histogramami dla poszczególnych atrybutów. - Użyj operatora
Data Samplerdo podzielenia zbioru na dwie części: 70% danych trafi do zbioru uczącego (ang. train set), a 30% danych stanowić będzie zbiór testujący (ang. test set) - Prześlij zbiór uczący do operatora
Naive Bayes. - Posłuż się operatorem
Predictionsdo wykonania predykcji na zbiorze testującym. - Czy na podstawie poprzedniego przepływu możesz oszacować dokładność klasyfikatora?
- Usuń operator próbkujący dane i prześlij całość danych do operatora
Test Learners. Drugim parametrem wejściowym operatora jest konkretny algorytm uczący, prześlij więc na wejście operatoraTest Learnersalgorytm naiwnego klasyfikatora Bayesa. W ustawieniach operatoraTest Learnerszaznacz, że operator ma dokonać podziału na zbiór uczący i testujący w proporcji 70%-30%. - Obejrzyj wynik testu. Prześlij ten wynik do operatora
Confusion Matrixi obejrzyj wynikową macierz pomyłek. - Zmień sposób walidacji klasyfikatora na 10-krotną walidację krzyżową. Czy ta zmiana spowodowała zmianę w macierzy pomyłek i ogólnej dokładności klasyfikatora?
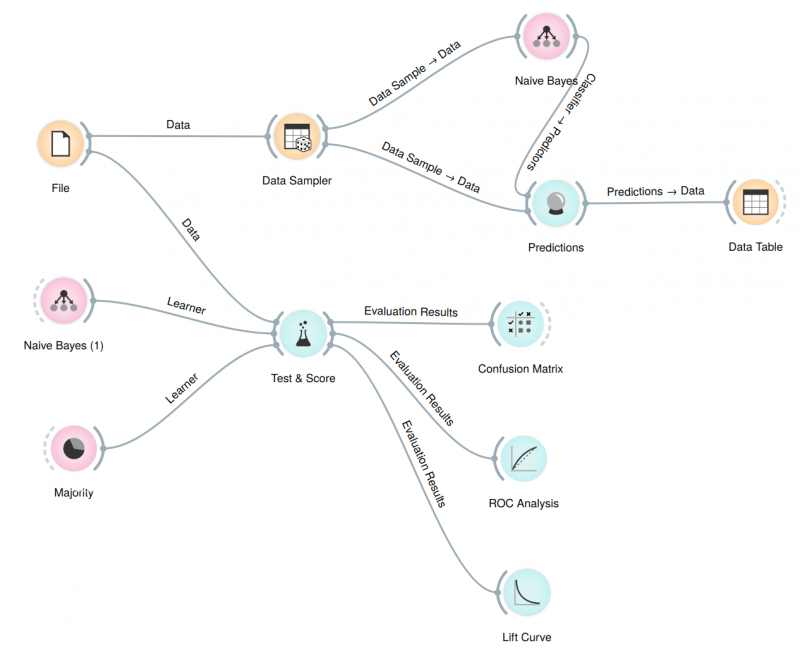
- Twój ostateczny przepływ powinien wyglądac tak:
Python
- Zapoznaj się z dokumentacją SciKit Learn dotyczącą naiwnego klasyfikatora Bayesa
- pobierz notatnik i uruchom go lokalnie lub przy użyciu https://jupyter.org/try
zadanie samodzielne
Samodzielnie zbuduj i przetestuj naiwny klasyfikator Bayesa na zbiorze smsspamcollection.csv. Możesz do tego celu wykorzystać dowolne narzędzie (RapidMiner, Python, R, Orange Data Mining). Wyniki prześlij na adres Mikolaj.Morzy@put.poznan.pl do niedzieli, 10 maja, godz. 21:00. Jeżeli realizujesz zadanie w notatniku/kodzie Pythona, prześlij ten kod. Jeśli wykorzystujesz RapidMiner lub Orange Data Mining, prześlij plik `*.pdf` zawierający dwa zrzuty ekranu: zrzut pokazujący cały workflow, oraz zrzut pokazujący macierz pomyłek. Zadanie uznam za zrealizowane, jeśli ogólna dokładność klasyfikatora będzie większa niż 90%.